Gemini Robotics-ER 1.6: Robots That Finally Understand the World


The gap between what AI can reason about and what a robot can actually do in the physical world has long been the hard ceiling of industrial automation. Google DeepMind just made that ceiling a lot higher.
Gemini Robotics-ER 1.6, released today by Google DeepMind, is a significant upgrade to their reasoning-first robotics model—one that doesn’t just improve benchmark numbers but unlocks entirely new categories of physical task that were previously intractable for autonomous systems.
Key Takeaways
- Gemini Robotics-ER 1.6 is available now via the Gemini API and Google AI Studio, accessible to developers building physical agents.
- Pointing & counting accuracy jumps from 61% (ER 1.5) to 80%, a foundational capability for spatial reasoning and object manipulation.
- Multi-view success detection reaches 84%, enabling robots to understand task completion across multiple simultaneous camera feeds.
- Instrument reading is a brand-new capability, unlocking autonomous industrial inspection—developed directly with Boston Dynamics for their Spot robot.
- Safety benchmarks improve substantially, with +6% on text hazard recognition and +10% on video-based injury risk over Gemini 3.0 Flash baseline.
- The model acts as a high-level reasoning layer, natively calling tools like Google Search, vision-language-action (VLA) models, and third-party functions.
Why “Embodied Reasoning” Is the Real Bottleneck
Most discussions about AI in robotics treat the hardware as the constraint. The actuators, the sensors, the power budget. But anyone running industrial automation at scale knows the deeper problem: spatial intelligence.
A robot arm guided by a traditional vision system can pick a widget from a tray—assuming the tray, lighting, and widget orientation are exactly as programmed. Introduce an occlusion, swap the camera angle, or ask it to count objects under variable lighting, and the system falls apart. These aren’t edge cases. They’re the average of what happens in a live facility.
Embodied reasoning models like Gemini Robotics-ER 1.6 attack this differently. Rather than hard-coded vision pipelines, the model applies genuine spatial cognition: it understands relationships between objects, can reason about what it can’t see, and maintains coherence across multiple camera feeds simultaneously. This is the class of intelligence that bridges the gap between digital AI and physical action.
Pointing: More Than It Sounds
The benchmark gains in pointing—from 61% to 80% success rate over ER 1.5—might look like a minor incremental improvement. It isn’t.
Pointing is the foundational primitive of physical reasoning. When a model can accurately point to an object, it can:
- Count items in complex, cluttered scenes with precision
- Establish relational logic (identify the smallest item, define a “from-to” trajectory)
- Map grasp points for downstream action models
- Reason through constraints like “point to every object small enough to fit inside the blue cup”
ER 1.6 also demonstrates improved negative precision—knowing when not to point. When asked to locate a wheelbarrow and a Ryobi drill not present in the scene, 1.6 correctly abstains. ER 1.5 hallucinated both. In physical AI, false positives aren’t just wrong answers—they’re potential equipment damage or safety incidents.
Success Detection: The Engine of True Autonomy
Anyone who has tried to deploy a fully autonomous robotic loop knows the failure mode: the robot completes an action but has no reliable way to verify it succeeded. Did the pen land in the holder, or did it miss? Did the lid seal properly, or is it slightly off? Without reliable success detection, you’re not running autonomy—you’re running supervised automation.
Gemini Robotics-ER 1.6 advances multi-view success detection to 84% (vs 74% in ER 1.5), and makes a qualitative leap in how it handles multi-camera environments. Industrial robotics setups routinely include overhead feeds, wrist-mounted cameras, and fixed inspection stations. ER 1.6 synthesizes these viewpoints into a coherent understanding of task state—even when one view is partially occluded or the object moves between frames.
This is the capability that turns robotic arms into autonomous agents. When the model knows what “done” looks like, it can decide whether to retry, proceed, or escalate to a human—without a human watching every cycle.
Instrument Reading: A New Frontier, Born from Boston Dynamics
The most commercially significant capability in ER 1.6 is one that didn’t exist in any previous version: instrument reading.
This capability was developed in direct collaboration with Boston Dynamics, and it’s tailored to a critical industrial use case—autonomous facility inspection with Spot. Across manufacturing plants, utilities, and chemical facilities, thousands of instruments require periodic human inspection: pressure gauges, thermometers, flow meters, chemical sight glasses. It’s repetitive, expensive, and difficult to automate because it requires genuine visual reasoning.
ER 1.6 solves this through what Google calls agentic vision: a multi-step reasoning loop where the model:
- Zooms in on the gauge to resolve fine detail
- Uses pointing to identify the needle, tick marks, and scale boundaries
- Executes code to estimate proportions and derive the accurate reading
- Applies world knowledge to interpret units, multi-needle interactions, and liquid level distortion in sight glasses
The benchmark numbers tell the story: on instrument reading with agentic vision enabled, ER 1.6 hits 93%—compared to just 23% for ER 1.5 (which doesn’t support agentic vision) and 72% for Gemini 3.0 Flash.
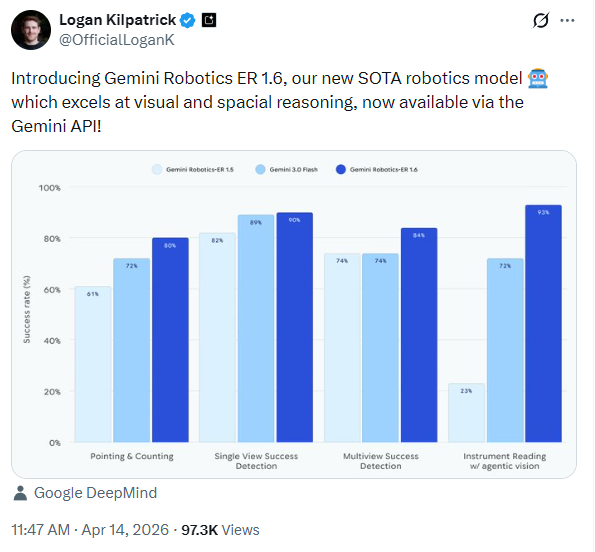
Logan Kilpatrick, Google DeepMind’s head of developer relations for Gemini, announced the release on April 14, 2026. The benchmark chart shows ER 1.6’s dominance across all four core evaluation categories.
The Architecture: High-Level Reasoning, Not Low-Level Control
An important clarification for enterprise architects evaluating this technology: Gemini Robotics-ER 1.6 is not a low-level motor control model. It operates as the reasoning layer—the “brain”—while downstream vision-language-action (VLA) models handle the physical motion execution.
This separation of concerns matters. The ER 1.6 model can:
- Call Google Search natively to retrieve real-time information mid-task
- Invoke third-party VLA models for dexterous manipulation
- Execute arbitrary user-defined functions for custom enterprise integrations
- Reason across time about task state and multi-step plan execution
This architecture mirrors what we’ve seen drive success in the broader physical AI enterprise revolution: modular stacks where a high-intelligence reasoning model orchestrates specialist action models, rather than a single monolithic system trying to do everything.
Safety by Design, Not by Afterthought
One of the subtler improvements in ER 1.6 is the safety posture. The model shows substantially improved compliance with physical safety constraints: instructions like “don’t handle liquids” or “don’t pick up objects heavier than 20kg” are now respected at the spatial reasoning level—the model uses pointing to determine whether an object violates a constraint before recommending action.
This is architecturally significant. Safety encoded at the reasoning layer, not bolted on at the policy layer, is far more robust in practice. The model also improves on ASIMOV v2 benchmarks for real-world injury risk detection in both text and video scenarios—testing based on actual industrial injury reports.
For enterprises in regulated industries, this matters as much as the accuracy numbers.
What This Means for Industrial Operators
The benchmark jumps in ER 1.6 represent something concrete for industrial operators:
Autonomous facility inspection is no longer a roadmap item. Spot + ER 1.6 is a deployable system that can walk a facility, read every instrument autonomously, and flag anomalies—today, via the Gemini API.
Robotic pick-and-place loops with genuine autonomy become more viable. The improved success detection removes the requirement for a human in the verification loop on every cycle.
Multi-robot coordination becomes more tractable when each robot’s high-level reasoning model can independently interpret multi-view camera data without a centralized vision system.
This aligns directly with the trend we identified in our analysis of agentic AI’s transformation of enterprise workflows: the shift from AI as an assistant to AI as an autonomous operator is accelerating on the physical layer, not just in software.
Developer Access: Available Now
Gemini Robotics-ER 1.6 is available today on Google AI Studio for developers. The Gemini API documentation includes a dedicated robotics overview, and Google has published a Colab notebook with configuration examples and prompting patterns for embodied reasoning tasks.
If you’re building specialized robotic applications where current capabilities fall short, DeepMind is actively soliciting collaboration—submitting 10–50 labeled failure-mode images directly improves the model’s next training cycle.
Final Thoughts
Gemini Robotics-ER 1.6 is not an incremental model update. The instrument reading capability alone—a use case that didn’t exist in the prior generation—represents the opening of an entire vertical: autonomous industrial inspection. Add the gains in multi-view success detection and pointing precision, and you have a meaningful step toward the autonomous physical agent that the robotics industry has been promising for a decade.
The fact that this is available via API today—without specialized hardware procurement cycles or enterprise contracts—means the barrier to piloting this technology is lower than at any previous point in physical AI’s history.
The question for operations leaders isn’t whether to evaluate this. It’s which facility inspection, quality verification, or logistics loop you run the first pilot on.
Sources: Google DeepMind — Gemini Robotics-ER 1.6 | Boston Dynamics — AIVI Learning Now Powered by Google Gemini Robotics | Google Developers Blog — Gemini Robotics-ER 1.5


